今回もやってまいりました。「IT業界で使いそうな言葉その3」です!

今回の用語は「インフラ」に関わるIT用語です!
インフラとは、サーバなどの「基盤」の部分を指す言葉。
インフラ用語はいっぱいあるのですが、よく使いそうなものをチョイスしました!
それでは、今回も半分真面目、半分不真面目に語ります!

インフラ
インフラとは「インフラストラクチャ」の略で「産業基盤」って意味です。
ITでいう産業基盤とは、サーバーやら通信機器、回線、施設などなど、システムを動かすための「基礎の部分」を指します。
電車で表現すると、電車を動かすための「線路とか電線」みたいなもんです。

なので「インフラエンジニア」と呼ばれる人たちははサーバーやネットワークの技術者を指すことが多いです。
※インフラを3行で説明すると?

2:機器がいっぱいならんでる
3:これがまさにインフラ環境
オンプレミス
いわゆるクラウドの反対語で、略して「オンプレ」と言う人が多いです。
クラウドはインターネットの先にあるインフラ環境を借りてますんで、自前でサーバーや通信機器を持つ必要がありません。
それに対しオンプレの場合は、サーバーや設置場所を自前で用意し、管理も自前で行う事を指します。

では何故自前で持たなければいけないのでしょう?
例えば、金融系で大きなトラブルが起きると、社会を巻き込んだ大事件になりますよね?

なので、クラウドを利用する事に高いハードルがあるんです。
この業界のシステム環境は、インターネットに接続するというのはあり得ません
物理的にも厳重にクローズされた環境で取り扱ってます。
つまり、クラウド環境を信用せず、自分の身は自分の力で守っている訳です。

もし何かあったら、クラウドサービスの業者ではなく、クラウドサービスを利用していた企業が責任を問われます。
便利や効率を考える前に、僅かなリスクも見逃さず、死守しなければいけません。
あ、でも最近は金融系もちょっとずつ部分的にクラウド化している様です。
時代の流れについていくのも大事なんでしょうね。

時代の方がもうかってた気がする!
だってハードや設備代入れるとすぐに
億を超えるんだぜ?
スケールアップ
これ類似用語があるのでちょっと注意です。スケールアップはCPUやメモリを増設してサーバーの性能をあげる事です。
単純に意味としてはこれだけで、難しい事はありません。
ポイントとして「スケールアップ」は、サーバー1台だけを増強していくので、上限値があるという事です!
※カンフー映画風 用語利用例
増強してスケールアップしたい。
しかし本当にそれは正しいのか
俺には解らないんだよ!

スケールアウト
スケールアップに言葉が似てるので間違えやすいのですが、こちらはサーバーの台数を増やしてシステムの性能をあげる事を指します。
サーバのスペックではなく、台数を増やし、並列に動かす事で性能をあげるイメージです。
例えば、2台で分散させて稼働させてたサーバーを、1台増やして3台で分散させたりみたいな感じですね。
この構成のメリットスケールアップの様に上限値を意識する必要はありません。
しかし予め、スケールアウト可能な設計をしておく必要があるのが特徴です。
こちらは、比較的規模の大きなシステムなどで使われやすいのが特徴です。
※Zガンダム風 利用例

冗長化
サーバーやネットワーク機器が故障しても業務が停止しない様に、まったく同じ設定の予備を用意しておき、不慮の事故や故障に備える事です。
よくある予備電源に近いかな?ちなみにここから下は冗長化の方法についての用語となります!
フェイルオーバー
こちらは冗長化とセットになる話です。
サーバーなどを冗長化する場合、よくあるやり方が、本番用(アクティブ)と待機用(スタンバイ)のサーバーをそれぞれ用意します。
本番用と待機用のサーバーは、互いに常にちゃんと稼働をしているか確認を行っています。
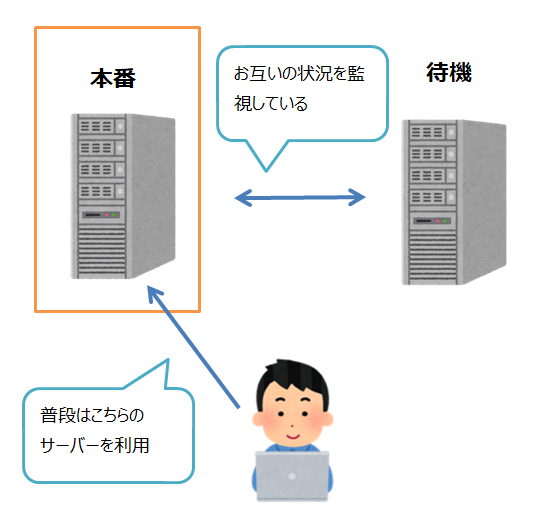
もし本番用から確認の返事が来なくなったら、自動的に待機用が本番用に変わるような仕組みになってます。
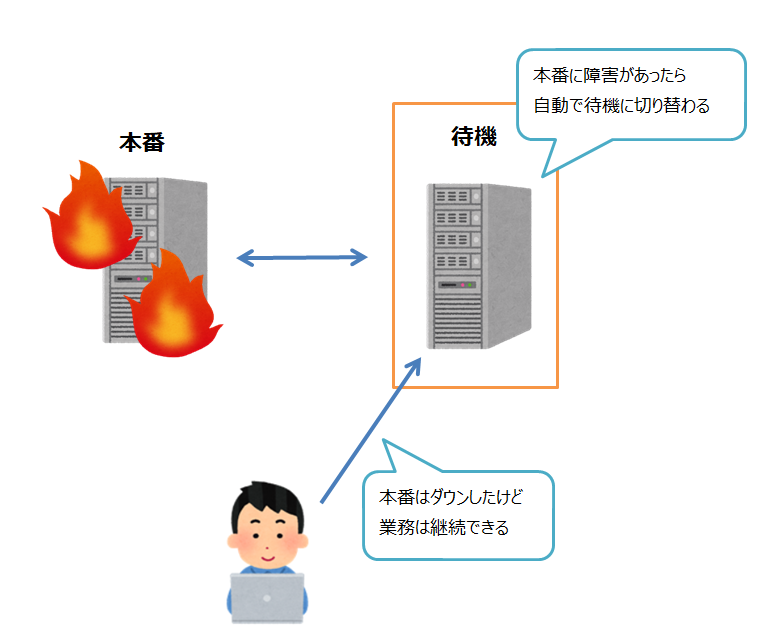
この仕組みを使って、待機用が本番用に切り替わる事を「フェイルオーバー」っていいます。
こうすれば障害があってもすぐに業務ができるようになりますよね。!
でもぶっちゃけ、切り替わらない事も結構あった!

そしてこの流れに突入・・

フェイルバック
フェイルオーバーは、本番用のサーバーに障害が発生したら。待機用のサーバーが自動的に本番用になるというお話をさせていただきました。
フェイルバックはもともと使われてた本番を復活させます。
そして待機用から本番用に切り替わったサーバーを「待機用」に戻して、元通りの環境に戻します。これをフェイルバックっていいます。
でもぶっちゃけ、元通りに戻らない事も結構あった!
そしてこの流れに突入・・

再発防止策
再発防止策って、障害対応の経験がある人には、おなじみの言葉ですよね。
障害の原因がオペミスだった場合は、再発防止策で「これからはダブルチェックを実施します!」みたいな流れになります。
でも、それでも間違う事ってあるんですよ(人間だもの)最近のIT業界めっちゃ忙しいし大変だし。
さて、じゃあダブルチェックがだめなら、次の再発防止策はどうなるでしょう?

ここでたまに出てくるのが「トリプルチェック」!
トリプルチェックする事で、うまくいくのでしょうか?実際、私はこれで解決した例をみた事がないです。
ツイッターでちょっと前にバズってましたが、大体こうなって状況が悪化します。
いやいや・・マジでホントにこうなるんですよ!
トリプルチェックの弊害 #現場猫 pic.twitter.com/jVkujwrphV
— からあげのるつぼ (@karaage_rutsubo) August 2, 2019
やたらテンプレ化しすぎたり、一方的にお客の言う事を聞きすぎたりすると、焼け石に水であんまし改善されません。
本当の改善案(再発防止策)は双方で情報を共有して折り合いをつけ、調整をしないと良い結果にはならないんですよね。
最後にどうでもいい余談
最後に再発防止策について、どうでもいい余談です!
私がよく行く焼き肉屋は、過去他のチェーン店でO157や食中毒が出た事があります

こういう事があると、再発防止策として新しいルールとして、トングの種類がどんどん増えていく傾向がある様です。
直近では「焼き用トング」の他に「生肉つかみ用トング」が追加されました。
もし次回も類似の事象が発生してしまったら、再発防止策で、また新しい用途のトングが増えるのでしょうか?
今後の動向が気になるところです!

関連書籍(今回のテーマに近い書籍)



